03. 如何有效回答面试过程中的系统设计题
小伙伴们好,我是TopGeeky,一个大厂工作过四年的Java后端、大数据开发工程师。今年来,不论是校招还是还是社招,场景题的比重逐年提升,就2024的面试统计结果来看,1-3年的社招面试场景题的占比大概30-40%之间,而校招面试场景题占比也已经到了20%。
很多同学八股文背的流利但是在面试场景题上面就傻眼了,所以我总结了校招、社招常见的面试场景题,不仅仅是帮助更多同学还是为了总结知识点应对未来环境的变化。
这篇文章是介绍如何有效的回答面试中的系统设计题。
系统设计题的评分标准
在了解面试官最想要的评分标准之前,你必须要承认的一件事情就是,你永远都没办法回答出100%令面试官满意的回答!
这份评价标准的含义就是让你更好的达到及格线,以及引入接下来面试官想要提问你的问题!
面试过程中能够让时刻抛出钩子让面试官按照你的思路来提问,这场面试你就有了70%的胜利了!
跟很多面试官聊了很久之后发现,他们主要想要考察问题包括这么以下几点,以及权重
- 需求分析能力 20%
- 提出一个基础可行方案 25%
- 系统是否拓展以应对其他特定状况 20%
- 知识储备能力 20%
- Trade off理解能力 15%
在知道考点的情况下,应该如何答题,我就直接告诉小伙伴们的答题模板!
按照这个步骤来答题,让你的回答没有明显的漏洞和失误!一秒让面试官称赞你的答题思路!
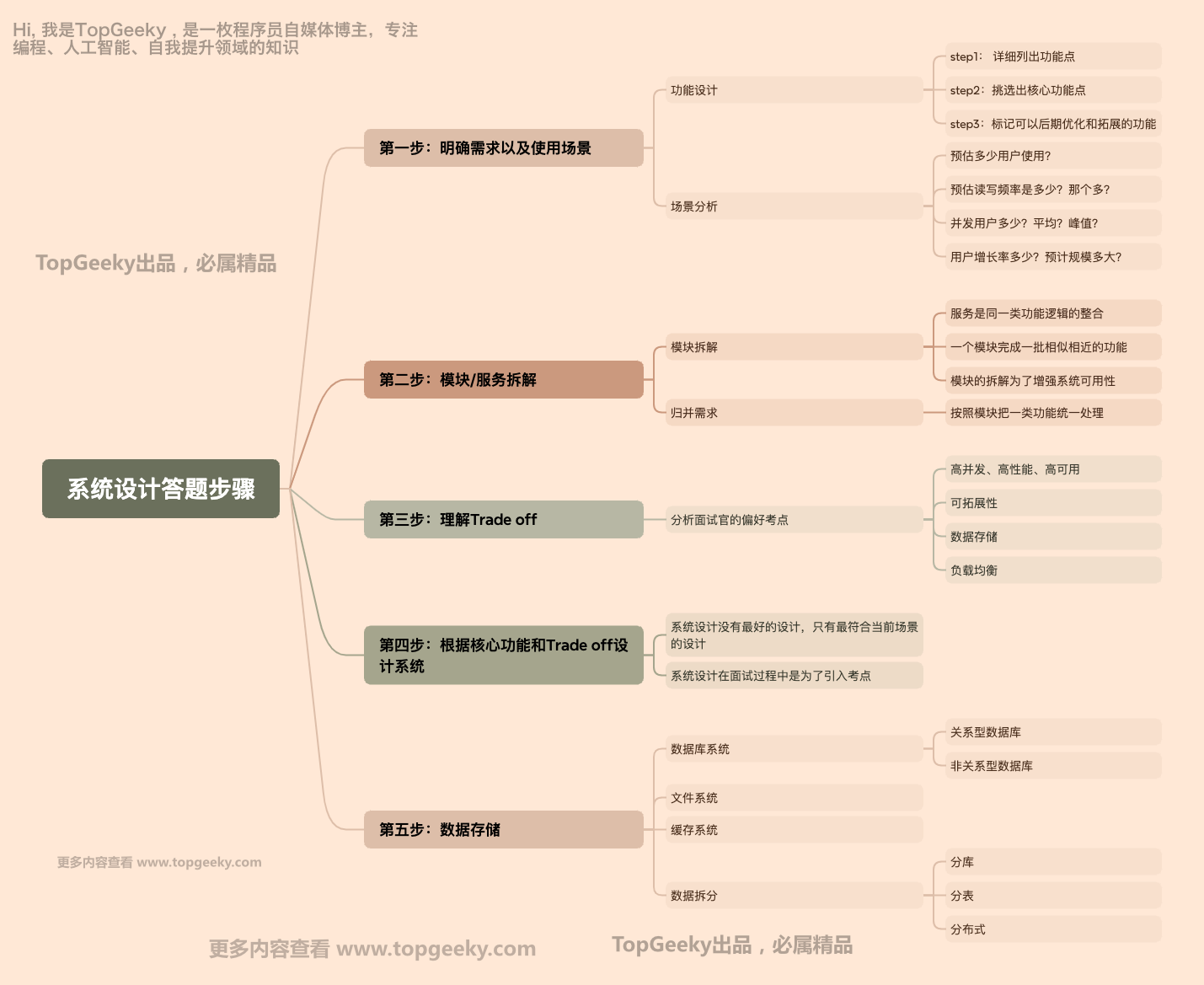
第一步:做好需求分析
这个环节是面试官对你的初印象!
在系统设计阶段和面试官互动最多的场景就是需求分析阶段,你需要问清楚面试官的场景,并且不断对细节提问,这一点是很加分的,这代表你对场景有很明确的思考。
但是这个阶段有的时候面试官也不一定能够给你足够反馈的回答!所以这个时候你一定要学会假设场景!假设场景!假设场景!
比如用户多少如果面试官也没有给你明确回答,那你就要回答大概10W用户可行不,然后再次基础上预估QPS等等!
如果没有这一步的场景假设,那你的系统设计根本经不清推敲!!
一般你需要询问面试官或者自己假定的场景包括以下内容:
- 系统面向的目标群体是什么?
- 系统的用户量有多少?
- 希望每分钟处理多少请求?
- 峰值请求最大能达到多少?
- 希望处理多少数据?
- 希望读频率和写频率是多少?
分析QPS的作用
- QPS = 100,那么用你的笔记本作Web服务器就好了;
- QPS = 1K,一台好点的Web 服务器也能应付,需要考虑Single Point Failure;
- QPS = 1m,则需要建设一个1000台Web服务器的集群,并且要考虑如何Maintainance(某一台挂了怎么办)。
QPS 和 服务器/数据库之间的关系
- 一台Web Server承受量约为 1K的QPS
- 一台SQL Database承受量约为 1K的QPS
- 一台 NoSQL Database 约承受量是 10k 的 QPS;
- 一台 Redis 约承受量是 500K QPS
第二步:模块、服务拆分
特别是现在考虑分布式架构的情况下,通常才有模块拆分和服务拆分。
对于同一类的问题往往采用同一个服务去处理,这样可以提高整体性能的可用性。
再选出核心功能的时候一般会对整个系统进行服务拆分,比如用户服务、存储服务、还有社交媒体的服务、电商的订单服务等等
第三步:理解Trade off
计算机领域常提到的问题就是Trade off,也就是永远没办法创建出来一个方方面面都是满分的系统,所以面对某一个特定场景下,我们更需要考虑如何设计出来更适应场景的系统。
在面试过程中,就是设计出来面试官所偏好的系统。
如果面试官考虑的是可用性,那你就要考虑系统故障排查、自愈系统、服务降级等等这方面的内容
如果面试官考虑的是高性能,那你就要考虑服务调用、网络优化、数据库优化、计算资源优化等内容
如果面试官考虑的是数据安全,那你就要考虑数据安全、数据一致性等问题。
第四步: 核心功能以及Trade off
在你完成前面几个阶段的分析后,这个环节的系统设计永远都不会偏离面试官想要的系统!!
拆解服务设计模块覆盖核心功能,通过理解面试官的Trade off才能更好的知道面试官想要考察的内容。
这样你设计出来的系统就有和面试官继续聊下去的可能
但是所有的系统设计都有一个隐含的条件,就是可以进行拓展和高性能、高可用、高并发优化!
这一点在系统设计时候就需要考虑这个隐含条件,不然后续的优化空间就丢失了。
另外,拓展和优化也是面试想要引入下一个话题的引子。
第五步:数据存储
在目前的系统当中,系统 = 服务调用 + 数据存储
一般来说,选择的存储结构一般有三大类:数据库系统,文件系统,缓存系统。
数据库系统
特点:
- 数据持久化: 数据库系统提供了数据的持久化存储,确保数据不会因为系统重启或故障而丢失。
- 数据一致性: 通过事务支持,数据库系统可以保证数据的一致性和完整性。
- 查询能力: 提供强大的查询语言(如 SQL),支持复杂的查询和数据操作。
- 并发控制: 支持多用户并发访问,同时保证数据的一致性和隔离性。
- 索引和优化: 通过索引和其他优化技术,提高数据检索速度。
常见类型:
- 关系型数据库 (RDBMS): 如 MySQL, PostgreSQL, Oracle。
- NoSQL 数据库: 如 MongoDB, Cassandra, Redis。
面试中的考虑因素:
- 数据模型: 选择适合应用的数据模型(关系型 vs NoSQL)。
- 读写比例: 根据读写比例选择合适的数据库类型(例如,读多写少的场景适合使用缓存层)。
- 扩展性: 考虑水平扩展和垂直扩展的能力。
- 事务支持: 是否需要强一致性和事务支持。
- 性能要求: 查询延迟、吞吐量等性能指标。
- 成本: 许可费用、硬件成本、维护成本等。
文件系统
特点:
- 大文件存储: 适用于存储大量二进制文件,如图片、视频、日志文件等。
- 分布式存储: 可以通过分布式文件系统(如 HDFS, Ceph)实现高可用性和可扩展性。
- 低成本: 相对于数据库,文件系统通常成本更低。
- 简单易用: 文件系统相对简单,易于管理和维护。
常见类型:
- 本地文件系统: 如 ext4, NTFS。
- 分布式文件系统: 如 HDFS, Ceph, GlusterFS。
面试中的考虑因素:
- 文件大小和数量: 处理大量小文件还是少量大文件。
- 访问模式: 随机访问还是顺序访问。
- 可靠性: 数据冗余和容错机制。
- 性能: 读写速度、延迟等。
- 成本: 存储成本和维护成本。
- 安全性: 权限管理和数据加密。
缓存系统
特点:
- 提高性能: 通过将频繁访问的数据存储在内存中,减少对后端数据库的访问,从而提高响应速度。
- 减轻后端压力: 缓存系统可以显著减轻数据库的负载,提高系统的整体吞吐量。
- 降低延迟: 内存访问比磁盘访问快得多,缓存系统可以显著降低数据访问延迟。
- 临时数据存储: 适合存储临时数据或会话数据。
常见类型:
- 内存缓存: 如 Redis, Memcached。
- 分布式缓存: 如 Redis Cluster, Hazelcast。
面试需要考虑因素
- 缓存策略: 选择合适的缓存淘汰策略(如 LRU, LFU)。
- 一致性: 缓存与数据库之间的一致性问题。
- 容量规划: 确定缓存的大小和扩展策略。
- 失效机制: 缓存项的过期时间和刷新机制。
- 性能监控: 监控缓存的命中率、未命中率等指标。
- 成本: 缓存系统的硬件成本和维护成本。