01.短链URL如何设计?百亿短链如何做到无冲突?
需求分析
目前互联网社交媒体,比如微博、简书等链接,如果是分享长网址链接,很容易就超出限制。因此产生的短链服务就是把长网址链接转为短网址链接,由此方便链接在社交网络上分享和传播。
短链的长度多少合适?
短链URL的可用的字符一共为62个(26个小写字母、26个大写字母、10个数字),所以这个时候可以预估一下一共有多少个长链接需要转为短链URL。
假设所需要转为短链的长网址链接一共需要 X 个,那么所需要的短链最低长度为:$log_{62}(x) + 1$,也就是向上取整。
在现在的社交媒体当中,像微博采用的短链长度就是7,由此估计长链接在 $62^7=3521614606208$ 以下
因此在估计短链长度的时候:
- 可以告诉面试官计算公式:$log_{62}(x) + 1$
- 也可以根据现有规模体谅来估计,一般以6-7个左右
短链服务采用301还是302?
先说一下301跳转和302跳转的区别,这两种跳转是用于网页重定向的HTTP状态码类型,主要区别在于指示浏览器如何处理请求以及搜索引擎如何处理这些重定向链接。
- 301 Moved Permanently(永久移动):
- 当一个网页被永久地移动到了一个新的位置时使用。
- 搜索引擎会将旧URL的权重转移到新URL上。这意味着如果网站从一个URL永久迁移至另一个URL,使用301跳转可以帮助保留原有的SEO价值。
- 浏览器接收到301响应后,通常会自动缓存这个重定向信息,以便未来直接访问新地址,而不再需要再次查询服务器。
- 302 Found(临时移动):
- 表示资源暂时位于不同的URI下。这可能是由于页面正在维护或内容只是短暂地迁移到了别处。
- 搜索引擎一般不会将旧URL的排名传递给新URL,因为这种重定向被认为是临时性的。
- 浏览器在遇到302响应时,虽然也会执行重定向到指定的新位置,但不会长期记住这一变化;每次用户尝试访问原始URL时,都需要重新向服务器发起请求来获取最新的重定向信息。
通常来说,短链的设计更多的采用302跳转,因为这样子的请求会通过**短链生成服务,**这样短链生成服务才能收集更多的信息,如果是由第三方服务产生,服务提供商更想要收集更多信息。
另外为了保存更多的信息,长链和短链不是采用一对一的形式,而是采用一对多的形式
一对一还是一对多映射?
一个长链接对应一个短链接?还是多个短链接? 这是一个很难抉择的问题。
关键点在于你是否只想保存链接信息,还是想要更多的保存分享信息?
尤其是在互联网领域,绝大多数服务都尽可能的保存更多信息,比如分享者的信息,分享的HTTP头部的User Agent信息等等,为了进一步做数据分析、挖掘信息价值。
为了保存这些信息,一个长网址常常应对多个短链信息。
短链生成时序图
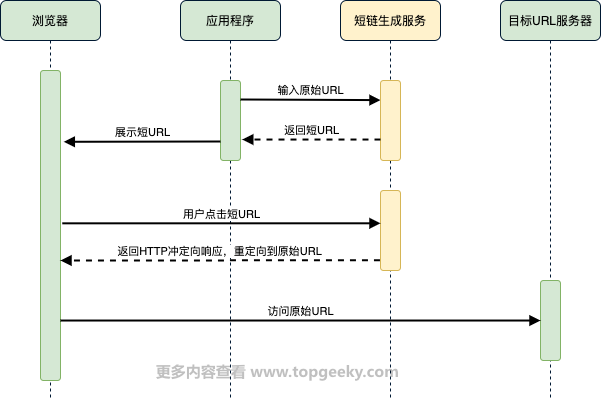
如何生成一个短链?
系统核心实现,包含三个大的功能
- 发号
- 存储
- 映射
可以分为两个模块:发号与存储模块、映射模块
发号与存储模块
- 发号:使用发号器发号 , 为每个长地址分配一个号码ID,并且需要防止地址二义,也就是防止同一个长址多次请求得到的短址不一样
- 存储:将号码与长地址存放在DB中,将号码转化成62进制,用于表示最终的短地址,并返回给用户
映射模块
用户使用62进制的短地址请求服务 ,
- 转换:将62进制的数转化成10进制,因为咱们系统内部是long 类型的10进制的数字ID
- 映射:在DB中寻找对应的长地址
- 通过302重定向,将用户请求重定向到对应的地址上
Hash算法
最容易考虑到的一点就使用Hash算法,对原始URL通过Hash编码得到对应的短链
哈希算法简单来说就是将一个元素映射成另一个元素,
哈希算法可以简单分类两类,
- 加密哈希,如MD5,SHA256等,
- 非加密哈希,如MurMurHash,CRC32,DJB等。
MD5算法
MD5消息摘要算法(MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,
可以产生出一个128位(16字节)的散列值(hash value),
MD5算法将数据(如一段文字)运算变为另一固定长度值,是散列算法的基础原理。
由美国密码学家 Ronald Linn Rivest设计,于1992年公开并在 RFC 1321 中被加以规范。
CRC算法
循环冗余校验(Cyclic Redundancy Check)是一种根据网络数据包或电脑文件等数据,
产生简短固定位数校验码的一种散列函数,由 W. Wesley Peterson 于1961年发表。
生成的数字在传输或者存储之前计算出来并且附加到数据后面,然后接收方进行检验确定数据是否发生变化。
由于本函数易于用二进制的电脑硬件使用、容易进行数学分析并且尤其善于检测传输通道干扰引起的错误,因此获得广泛应用。
MurmurHash
MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。
由 Austin Appleby 在2008年发明,并出现了多个变种,与其它流行的哈希函数相比,对于规律性较强的键,MurmurHash的随机分布特征表现更良好。
这个算法已经被很多开源项目使用,比如libstdc++ (4.6版)、Perl、nginx (不早于1.0.1版)、Rubinius、 libmemcached、maatkit、Hadoop、Redis,Memcached,Cassandra,HBase,Lucene等。
MurmurHash 计算可以是 128位、64位、32位,位数越多,碰撞概率越少。
所以,可以把长链做 MurmurHash 计算,可以得到的一个整数哈希值 。
那么,使用地址的hash 编码作为ID的问题是啥呢?
会出现碰撞,所以这种方案不能直接使用,需要有改进的空间。
数据库自增长ID
属于完全依赖数据源的方式,所有的ID存储在数据库里,是最常用的ID生成办法,在单体应用时期得到了最广泛的使用,建立数据表时利用数据库自带的auto_increment作主键,或是使用序列完成其他场景的一些自增长ID的需求。
但是这种方式存在在高并发情况下性能问题,要解决该问题,可以通过批量发号来解决,
提前为每台机器发放一个ID区间 [low,high],然后由机器在自己内存中使用 AtomicLong 原子类去保证自增,减少对DB的依赖,
每台机器,等到自己的区间即将满了,再向 DB 请求下一个区段的号码,
为了实现写入的高并发,可以引入 队列缓冲+批量写入架构,
等区间满了,再一次性将记录保存到DB中,并且异步进行获取和写入操作, 保证服务的持续高并发。
比如可以每次从数据库获取10000个号码,然后在内存中进行发放,当剩余的号码不足1000时,重新向MySQL请求下10000个号码,在上一批号码发放完了之后,批量进行写入数据库。
但是这种方案,更适合于单体的 DB 场景,在分布式DB场景下, 使用 MySQL的自增主键, 会存在不同DB库之间的ID冲突,又要使用各种办法去解决,
总结一下, MySQL的自增主键生成ID的优缺点和使用场景:
优点:
非常简单,有序递增,方便分页和排序。
缺点:
分库分表后,同一数据表的自增ID容易重复,无法直接使用(可以设置步长,但局限性很明显);
性能吞吐量整个较低,如果设计一个单独的数据库来实现 分布式应用的数据唯一性,
即使使用预生成方案,也会因为事务锁的问题,高并发场景容易出现单点瓶颈。
适用场景:
单数据库实例的表ID(包含主从同步场景),部分按天计数的流水号等;
分库分表场景、全系统唯一性ID场景不适用。
所以,高并发场景, MySQL的自增主键,很少用。
分布式、高性能的中间件生成ID
Mysql 不行,可以考虑分布式、高性能的中间件完成。
比如 Redis、MongoDB 的自增主键,或者其他 分布式存储的自增主键,但是这就会引入额外的中间组件。
假如使用Redis,则通过Redis的INCR/INCRBY自增原子操作命令,能保证生成的ID肯定是唯一有序的,本质上实现方式与数据库一致。
但是,超高并发场景,分布式自增主键的生产性能,没有本地生产ID的性能高。
总结一下,分布式、高性能的中间件生成ID的优缺点和使用场景:
优点:
整体吞吐量比数据库要高。
缺点:
Redis实例或集群宕机后,找回最新的ID值有点困难。
适用场景:
比较适合计数场景,如用户访问量,订单流水号(日期+流水号)等
UUID、GUID生成ID
UUID:
按照OSF制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片ID码和许多可能的数字。由以下几部分的组合:当前日期和时间(UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同),时钟序列,全局唯一的IEEE机器识别号(如果有网卡,从网卡获得,没有网卡以其他方式获得)
GUID:
微软对UUID这个标准的实现。UUID还有其它各种实现,不止GUID一种,不一一列举了。
这两种属于不依赖数据源方式,真正的全球唯一性ID
总结一下,UUID、GUID生成ID的优缺点和使用场景:
优点:
不依赖任何数据源,自行计算,没有网络ID,速度超快,并且全球唯一。
缺点:
没有顺序性,并且比较长(128bit),作为数据库主键、索引会导致索引效率下降,空间占用较多。
适用场景:
只要对存储空间没有苛刻要求的都能够适用,比如各种链路追踪、日志存储等。
snowflake算法(雪花算法)生成ID
snowflake ID 严格来说,属于 本地生产 ID,这点和 Redis ID、MongoDB ID不同, 后者属于远程生产的ID。
本地生产ID性能高,远程生产的ID性能低。
snowflake ID原理是使用Long类型(64位),按照一定的规则进行分段填充:时间(毫秒级)+集群ID+机器ID+序列号,每段占用的位数可以根据实际需要分配,其中集群ID和机器ID这两部分,在实际应用场景中要依赖外部参数配置或数据库记录。
总结一下,snowflake ID 的优缺点和使用场景:
优点:
高性能、低延迟、去中心化、按时间总体有序
缺点:
要求机器时钟同步(到秒级即可),需要解决 时钟回拨问题
如果某台机器的系统时钟回拨,有可能造成 ID 冲突,或者 ID 乱序。
适用场景:
分布式应用环境的数据主键
优化内容
如何判断是否发生了Hash冲突呢?
一般来说判断一个Hash是否冲突可以借助于数据库,毕竟所有的短链需要存储在数据库当中的通过查询数据中是否有重复的短链就可以判断是否发生Hash冲突。
但是这种方式十分慢,特别是高并发的场景下去查询数据可时是否不可取的。
最终应该采用的方式就是使用布隆过滤器来解决。
如何解决Hash冲突呢?
一般通过布隆过滤器可以发现Hash是否冲突,现在在面临真正Hash冲突的解决方式是什么呢?
一般来说有两种:二次Hash 和 唯一ID + 编码
二次Hash很好理解,就是对原来的Hash值再次经过Hash运算
唯一ID + 编码 就是采用类似于数据库这样的自增ID加上原来的Hash值,在通过Base62编码等技术将其转换为较短形式