07.如何设计一个百万级排行榜内容?
面试官考察知识点:
基础知识:候选人对排行榜系统的涵盖的数据库、缓存、Redis等知识的理解
系统架构能力:候选人如何构思整体架构,包括数据存储、更新机制以及查询效率。
性能优化:候选人如何优化系统以支持百万级的数据处理,包括索引、批处理、异步处理等。
安全性:如何保护排行榜数据的安全性,防止未授权访问。
候选人回答思路
在回答这种问题的时候,面试官无非及时想要知道以下这些知识点你有没有掌握清楚
- 如何实现高效的写入和读取操作。
- 如何处理大量的并发更新请求。
- 怎样保证排行榜数据的一致性和准确性。
- 在分布式环境下如何保证数据的一致性。
技术方案
接下来提出一个更有效的解决方案,那就是如何使用Redis的zset来实现排行榜功能,即使对于数百万用户,也能提供可预测的性能,并且允许我们轻松进行常见的排行榜操作,而无需依赖复杂的数据库查询。
了解过 Redis 常见数据结构的小伙伴,都知道 Redis 中有一个叫做 sorted set 的数据结构经常被用在各种排行榜的场景下。
通过 sorted set ,我们能够轻松应对百万级别的用户数据排序。这简直就是专门为排行榜设计的数据结构
Redis 中 sorted set 有点类似于 Java 中的 TreeSet 和 HashMap 的结合体,sorted set 中的数据会按照权重参数 score 的值进行排序。
Redis sorted sets有序集由两个数据结构实现:哈希表和跳表。哈希表将用户映射到分数,而跳表将分数映射到用户。在有序集中,用户按分数排序。
理解有序集的一种好方法是将其想象成一个包括分数和用户两列的表,如下图所示。表按分数降序排序。
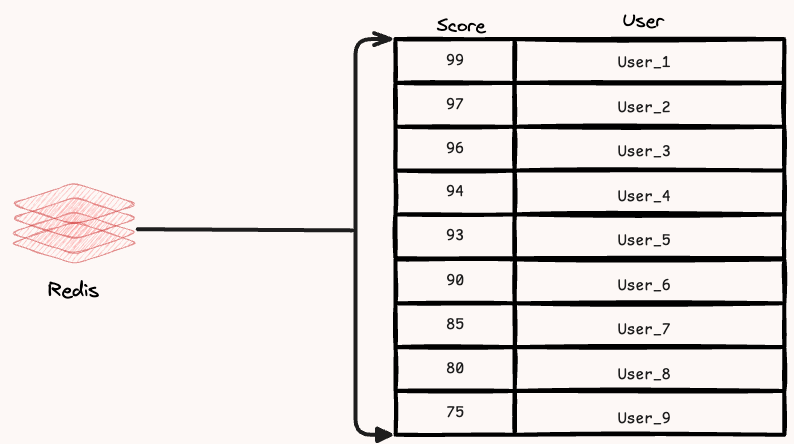
Redis sorted sets有序集是使用哈希表和跳表来实现的,具体关于Hash表和跳表内容的实现这里不展开赘述了,具体的内容可以直接查看Redis相关实现。
直接使用的问题
但是直接使用Reids进行排序在实际业务场景中会存在一些问题,如果存在分数相同的情况下,会按照Value的值排序,也就是用户的ID或者Name排序。如果想要根据相同分数的话,根据Score出现的时间排序的话,就需要对排序的Score做一些修改,比如添加上当前时间作为Score的一部分。
我们可以将分数score设置为一个浮点数,其中整数部分为得分,小数部分为时间戳,如下所示:
score = 分数 + 时间戳/1e13
假设现在的时间戳是1680417299000,除以1e13得到0.1680417299000,再加上一个固定的分数(比如10),那么最终的分数就是10.1680417299000,可以将它作为zset中某个成员的分数,用来排序。
当然这些还有存在很多排序的具体业务,基本上来都是都操作Score层面来进行分组排序的。
具体实现
基本操作:
ZADD:如果用户尚不存在,则将用户插入集合中。否则,更新用户的分数。执行时间复杂度为O(log(n))。ZINCRBY:将用户的分数增加指定的增量。如果用户在集合中不存在,则分数从0开始。执行时间复杂度为O(log(n))。ZRANGE/ZREVRANGE:按分数排序获取一定范围内的用户。我们可以指定排序顺序(range vs. revrange)、条目数以及要从哪个位置开始。执行时间复杂度为O(log(n) + m),其中m是要获取的条目数(在我们的场景中通常很小),n是有序集中的条目数。ZRANK/ZREVRANK:以对数时间复杂度获取任何用户在升序/降序排序中的位置。
如果我们要查看包含所有用户的排行榜怎么办? 通过 ZRANGE (从小到大排序) / ZREVRANGE (从大到小排序)
如果我们要查看只包含前 3 名的排行榜怎么办? 限定范围区间即可。
如果我们需要查询某个用户的分数怎么办呢? 通过 ZSCORE 命令即可。
如果我们需要查询某个用户的排名怎么办呢? 通过 ZREVRANK 命令即可。
如何对用户的排名数据进行更新呢? 通过 ZINCRBY命令即可。
拓展:如何实现指定日期(比如最近 7 天)的用户数据排序?
我说一种比较简单的方法:我们把每一天的数据都按照日期为名字,比如 20350305 就代表 2035 年 3 月 5 号。
如果我们需要查询最近 n 天的排行榜数据的话,直接 ZUNIONSTORE来求 n 个 sorted set 的并集即可。
我不知道大家看懂了没有,我这里还是简单地造一些数据模拟一下吧!
通过 ZUNIONSTORE 命令来查看最近 3 天的排行榜情况:
现在,这 3 天的数据都集中在了 last_n_days 中。
如果一个用户同时在多个 sorted set 中的话,它最终的 score 值就等于这些 sorted set 中该用户的 score 值之和。
既然可以求并集,那必然也可以求交集。你可以通过 ZINTERSTORE 命令来求多个 n 个 sorted set 的交集。
故障恢复
说到故障恢复还是老生常谈的问题,那就是如何进行冗余设计和备份以及分布式节点的切换,所有的故障恢复都是这三点内容来进行回答!
冗余设计: 可以设计Redis集群进行使用,每次同步更新所有的Redis数据
备份: 为了保证数据更好的备份,可以通过关系型数据库进行备份,比如可以定时或者实时更新MySQL的数据库的记录,一旦发生故障就从数据库中读取数据进行恢复。
分布式节点的切换: 含有多个Redis集群的情况下,可以采用节点的切换维持系统的高可用性。